二级缓存设计
本文根据阿里开源的JetCache和大佬同事用kotlin写的MutilCacheManager两个框架,来分析二级缓存应该如何设计。
我们一般的缓存有2种用法:
- 纯缓存。例如预算加减、分布式锁、配置信息。
- 多级缓存+数据库/外部接口调用。一般一级或者二级就够用了。
二级缓存通常是指:为了获取查询耗时较长的数据,以本地缓存+远程统一存储缓存,构建的两个层级的缓存。
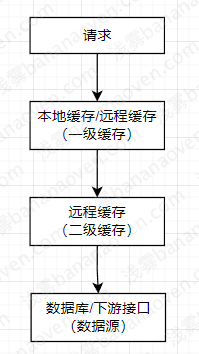
二级缓存需求点
- 兼容只使用一级缓存
- 支持自动后台异步刷新缓存
- 支持并发获取数据
- 支持监控:QPS、RT、命中率
- 支持key前缀、key、value序列化方式
- 能够处理空值
- 支持批量并发查询

实际应用场景示例:我要使用缓存,能够获取user的头像、性别等信息,缓存时间10分钟。查询可能是批量的,请求一系列用户的数据。由于查询并发量也很大,因此当缓存还剩2分钟过期时,后台异步自动重新加载,延长缓存过期时间,避免缓存击穿和雪崩。有些会员可能没有填资料,因此值为null,此时也希望把null值缓存起来,避免缓存穿透。用户如果更新了信息,那么应该能获取到最新的数据。我们运营的用户有中国、欧洲、美国,userId都是从1开始的,因此需要设置key前缀,以区分不同国家的用户。
二级缓存关键问题思路
一级缓存和二级缓存,应该使用哪些实现?
原则:按照速度划分,一级缓存用本地缓存或远程缓存,二级缓存只能用远程缓存。
一级缓存可以使用Guava、Caffeine,甚至ConcurrentHashMap自己写都可以。一级缓存使用远程缓存也是可以的,只需要保证一级和二级不一样即可,更高可靠。
二级缓存使用远程缓存,比如最常见的Redis、Memcached,或者一些云厂商的SaaS服务,如阿里云Tair,AWS的Elasticache。
查询和取出逻辑
- 查询:顺序查询,先查Level1缓存,不命中再查Level2缓存,还不命中再查数据库或者调用接口。
- 取出:应该逆向更新。查询到Level2有数据,回写Level1;查询到数据库或接口才有数据,那么先回写Level2,再回写Level1。

1 | V value = get(key, key -> { loader.load(key) }) |
批量查询如何实现
- 首先,批量查询,应该每个数据独立保存缓存,如使用Redis的mget,而不是用一个大key,除了性能不好以外,数据也不能复用。
- 当某些数据过期时,不是全量查询,而是只查缓存过期的那些数据。接口应该是这样的:
1
Map<K, V> data = getAll(keys, unCachedKeys -> { loader.load(unCachedKeys) })
处理空值
- 首先,存储的value不应该是原生value,因为这样区分不出来“查询不到返回null”还是“业务本身就存储了null”,应该存一个包装类,保证拿出来的数据一定存在。
1
class CacheData { private V value }
- 有些时候我们需要忽略空值,有些时候我们需要缓存空值避免穿透,需求并不是确定的。所以我们应该提供一个方法供用户填写到底要不要缓存空值,因此应该提供一个方法让用户自己决定
1
2
3
4
5
6
7V value = get(key, key -> {
V value = loader.load(key),
default boolean needCache(V value) { return true }
})
自动刷新如何实现
自动刷新的触发时机
“当缓存还剩2分钟过期时,延长缓存过期时间”,这个需求需要仔细理解。如果是“所有缓存都自动延长”,那这个缓存会越来越大直到存下数据库所有信息,这是没有意义的。因此这里指的是,当缓存还剩2分钟过期时,给活跃的缓存续命。活跃的判断标准当然是查询了,所以在第8分钟到第10分钟期间来查询的,都应该触发自动刷新。
自动刷新缓存时间配置
自动刷新,首先需要配置一个时间,这个时间应该是小于缓存时间的。不可能每个user都配置一个时间,因此一定需要一个{ PREFIX=”USER_” -> refreshTime } 这样的一个配置。接口应该是这样的:
1 | V value = get(prefix, key, loadFunction) |
判断是否过期
当查询到一个缓存时,如何判断要不要自动刷新?如果把PREFIX遍历一遍,效率太低啦。空间换时间,把过期时间存入缓存结构即可。
1 | class CacheData { private V value; private long expireTime; } |
并发请求
自动刷新遇到并发 假设这样一个场景:100个请求,在第9分钟的时候,同时查询userId=1的缓存。 此时有几种选择:
- 强行请求,100个请求,都去异步拿最新缓存,流量透传。不好。
- 1个加载新缓存,其他99个直接返回旧缓存。
- 1个加载新缓存,其他99个等待加载完成后,返回新缓存。如果加载失败,其他请求会卡死。
- 1个加载新缓存,其他99个等待加载完成后,返回新缓存。如果等待超时,则返回旧值或抛出异常。可以。
- 1个加载新缓存,其他99个等待加载完成后,返回新缓存。如果等待超时,则自己去加载。可以。
这里关键点是,如何设计一个可等待的锁。这个锁肯定不能全局一把锁,因此用ConcurrentHashMap来按照key进行分段,即:ConcurrentHashMap<key, Lock>,用putIfAbsent或者computeIfAbsent甚至synchronized来原子地抢锁。
可等待的锁,有很多实现,这里重要的特性是:其他线程只需要被唤醒拿结果,而不需要去抢占这个锁。所以可以用CountdownLatch(1)、甚至Future,来实现。
用户更新数据,如何让缓存失效
远程存储很简单,直接失效即可。对于内存存储,每台机器都有自己的内存,因此需要一个中间件来将“缓存失效”事件告知到所有机器。广播方式就很多了,比如Redis、Kafka、RocketMq。
主要逻辑流程图

一些有意思的实现
并发初始化
JetCache一般会这样做初始化,双重校验锁:
1 | private volatile boolean inited = false; // 用volatile禁止语义重排 |
而同事喜欢这么初始化,CAS:
1 | private final AutomicBoolean inited = new AutomicBoolean(); |
可重入锁
JetCache在自动刷新的锁上面,实现了本线程可重入。可重入其实很简单,如果是单个线程可重入,那么在锁信息里面增加Thread即可。
1 | loaderLock.loaderThread = Thread.currentThread() |
分布式锁
JetCache单独做了一个AutoReleaseLock的分布式锁,生成一个随机UUID作为value,通过对比value是否一致,来拒绝其他机器、进程、线程持有锁。底层实现是setnx。

