百度IoT:MQTT_Broker架构设计
百度IoT的Broker设计我特别想参考的但是技术能力和时间不够去实现……网上只有一篇百度工程师的总结《共享行业的分布式MQTT设计》,这里将围绕这篇文章去讲解。
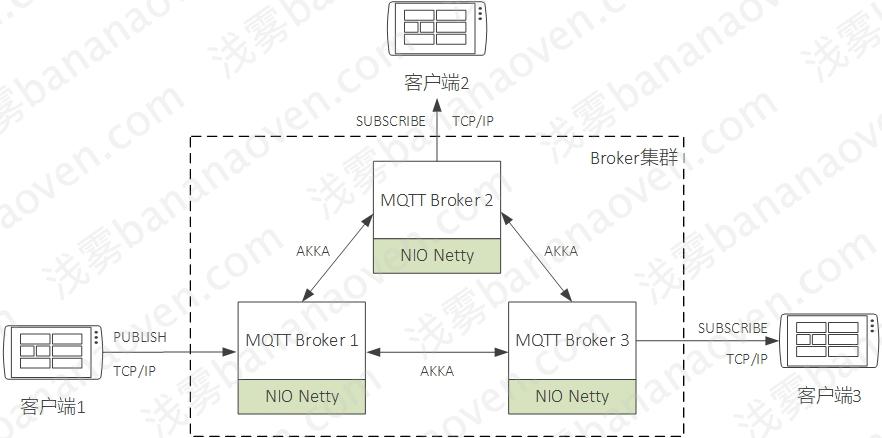
Broker集群架构
单机版MQTT Broker有连接数量和并发处理能力的限制,因此分布式必不可少。百度IoT采用的Akka Cluster来做集群管理,每个节点对等,不存在像Mosquitto这种用一台机器“桥接”做分布式产生的单点故障隐患。每个节点监听MemberUp、MemberDown、MemberUnreachable、ClusterMemberState等事件来感知其他节点的上下线,用Akka Actor实现节点间的消息通信。
Broker服务框架

百度Broker抽象了很多服务包括:
Authentication Service、Authorization Service
MQTT的CONNECT阶段提供username和password,Broker可以用这些数据对客户端身份进行校验,我们称为验证(Authentication,AE);MQTT的PUBLISH、SUBSCRIBE阶段,需要对客户端订阅主题、发布主题进行权限控制,比如只能订阅含有自己DeviceID的主题,避免客户端订阅他人的主题窃听信息,我们称为鉴权(Authorization,AO)。
百度Broker提供用户名、密码的认证,以及每个客户端对哪些主题可读、可写。实现上,数据全保存在Mysql,通过内存或Redis做Cache加速,Cache回收策略为LRU。
百度这样的做法只适合于固定权限的控制,比如设备拥有的权限几乎相同,而且都是订阅格式相似的主题,只有其中的clientID不同而已,就可以做。如果有权限动态变化、设备粒度划分更细致的情况,采用Mysql+Redis就行不通了。Session Manager
MQTT定义了两种会话:持久会话(Persistent Session)、非持久会话(Transient Session)。持久会话在客户端断开重连后,之前的订阅数据、离线期间接收的消息依然存在;非持久会话断开连接就清空所有数据。对分布式Broker而言,如何实现持久会话就是一个难点。百度Broker的策略是,持久会话每个Broker都会同步一份,即使Broker宕机,其他Broker上也有相应的信息,以解决高可用问题;非持久会话放在内存里,只在连接的Broker上存在,连接断开或Broker崩溃后清空。
文中没有提到如何解决跨区问题(跨区时延高容易掉线,最好不做集群而是做数据同步,多个区域的Broker Session应该如何同步),以及Session每个节点都同步一份导致内存随设备数量线性增长的问题。Event Service
负责将每个Broker上发生的连接事件、断开连接事件、订阅事件、取消订阅事件通过Event Service发送给每个Broker,以达到同步的目的,类似于消息总线。实现上采用的Kafka,没有采用Akka通信的原因是这些事件需要持久化,比如Broker崩溃、网络波动后之前发送的未被消费的事件还存在。
文中没有提到订阅事件、取消订阅事件如何处理顺序消费的问题,因为订阅和取消订阅先后顺序会影响Session的同步,比如同一个主题,客户端取消订阅事件先于订阅事件被消费,会导致一直订阅着某个主题;相反订阅事件先于取消订阅事件,会导致订阅丢失。通过kafka的方式,如果用了重试策略保证可靠性,就可能导致这些问题。虽然客户端订阅后马上取消订阅这种情况几乎不存在,都是上线后订阅、下线前取消订阅。Session State Metadata Service
负责持久化Session元数据,它从Event Service接收数据,然后决定哪些数据需要持久化到Hbase存储,比如持久会话的订阅、取消订阅数据。Queue Service
管理和分配Queue。根据Session类型不同,分为持久队列(Persistent Queue)、非持久队列(Transient Queue),用于消息下发和离线消息存储。Persistent Queue基于Hbase实现,Transient Queue是内存实现。Quota Service
管理并发连接数、上行带宽、下行带宽限制。Metric Service
监控并发连接数、并发消息数、当前流量、服务运行指标(CPU、内存、网络吞吐)
连接层
百度的连接层编解码架构如下:
百度Broker连接层采用Netty NIO框架,目前大多数MQTT Broker也都是这样做的,没有任何问题。提供四种基本方式:MQTT TCP、MQTT TCP+TLS、MQTT Websocket、MQTT Websocket+TLS。现在SSL大多指代TLS,SSL是早期版本(现在很多组件已经弃用),后来都升级到TLS了,TLSv1/1.1/1.2/1.3是目前最常用的版本,很多组件原生支持TLS全版本,所以开发很简单不必担心,可以参考开源Broker Moquette。而且我们经常会使用负载均衡器LB来终结SSL,终结的意思是LB对外提供SSL的接口,转发进来的数据都是TCP了,EMQ也推荐使用这种方式,经历过云平台搭建的大佬们也都推荐使用这种方式,因为SSL编解码会消耗CPU,由LB来做完SSL处理,前端连接机器负载会小很多,连接就会更稳定不容易崩溃。所以最后只要做TCP、Websocket两种方式就好了。MQTT Websocket指的是,将MQTT协议作为subprotocol,利用Websocket来透传MQTT协议数据。
持久化Session的处理方式
持久化Session,需要同步Session信息到每台机器,每台机器都有全局Session(相当于无状态)。当Broker宕机时,Session中的订阅数据依然存在,所以可以由其他Broker将Publish消息作为离线消息存入客户端在HBase对应的队列中去;当客户端从其他Broker重连时,Session的数据还在、HBase保留了掉线期间的全部消息并会在CONNECT阶段下发给客户端,客户端不会丢失任何信息。
连接阶段和虚拟队列
连接阶段没有相应的描述,这一段只是推测,流程图如下:
- 客户端以持久Session向连接节点Broker1发起MQTT-CONNECT请求,请求连接
- Broker1接收请求,产生连接事件,发往Event Service
- Event Service(Broker1上的)将订阅事件发布到Kafka
- Event Service(多个Broker上的)从Kafka消费订阅事件消息
- Event Service(多个Broker上的)将消息分发给各自的Broker
- 每个Broker都会创建对应的Session,包含了连接信息
- 其他节点往连接节点Broker1发一个内部通信消息,表明连接结果
- 连接节点Broker1综合连接结果,下发CONNACK给客户端,连接阶段结束
订阅消息流程
订阅主题的事件消息会发往Event Service,每个Broker都会订阅Event Service的数据,对于持久化Session,在接收到订阅事件后,会创建对应Session的订阅信息。也就是说,每个客户端产生的订阅、取消订阅操作,会被广播给所有Broker节点,Broker接收到后对内部的订阅树、Session等数据结构进行增删,保持订阅信息的一致性。
订阅的流程图如下:
- 客户端以持久Session向连接节点Broker1发起MQTT-SUBSCRIBE请求,请求订阅主题
- Broker1接收请求,产生订阅事件,发往Event Service
- Event Service将订阅事件发布到Kafka
- Event Service(多个Broker上的)从Kafka消费订阅事件消息
- Event Service(多个Broker上的)将消息分发给Broker
- 每个Broker都会创建对应的Session,记录这个客户端的订阅信息
- 其他节点往连接节点Broker1发一个内部通信消息,表明订阅结果
- 连接节点Broker1综合订阅结果,下发SUBACK给客户端,订阅结束
这里提到了一个虚拟队列(Virtual Queue)的概念。我们都知道MQTT要求持久化Session要缓存离线消息和未确认的QoS1消息,常用的做法就是把这些消息放到一个队列里面。对于单点而言,只需要放到内存就可以了,因为客户端只会连接一个节点;对于分布式而言,由于客户端可能会切换节点,放到一台机器的内存里在另一台机器上就无法访问了,百度采用了通用的分布式系统处理数据一致性的方案:计算和存储分离——将存储层单独做成一个集群,计算层做一个“虚拟队列”,只记录队列的状态,当需要获取数据时就利用这些“队列元数据”去存储层获取,保证无论在哪个节点上线,都可以获取到数据。
做队列存储的难点在于,目前并没有组件直接提供所需队列功能。第一个肯定会想到使用消息队列(Message Queue, MQ),但是分析下需求,我们需要海量的(和客户端同数量级)、较小的(每个队列可能最多100条消息)队列,目前类似Kafka这样的MQ,都是少量的(Kafka上百个Topic就会速度慢下来)、海量的(囤积大量待消费消息)队列,所以根本不符合需求。第二个想到的就是Redis,像Redisson这样的工具提供了队列的功能,实现上是将Lua脚本发送给Redis执行来实现队列的功能,但Redis用的是内存比较贵,并且Redis更适合做缓存而不是持久化存储。第三个就是自己研发了,有大佬自己基于RocketMQ研发了海量小消息队列,而百度是基于HBase数据库做的海量小消息队列,阿里也有一个基于HBase制作的HQueue,不过是收费的不开源。有关百度HBase队列实现细节将在后面叙述。
发送消息流程
发送消息的流程图如下:
- 客户端2发布一条消息给Broker2(不考虑QoS,因为QoS0也是可以这样操作的)
- Broker2拥有全局Session,发现客户端1订阅了这个主题,因此将消息写入客户端1的虚拟队列
- Broker2向Broker1发送一个通知(Notification)消息,告诉它有新消息可以消费了
- Broker2从虚拟队列读出数据,然后发布给客户端1,发布-接收流程结束
我们分析一下宕机高可用的原理。当Broker2因为进程挂掉、掉电、网络波动等等宕机了造成客户端1掉线,Broker2会继续往HBase写客户端1待消费消息,HBase是集群因此高可用;等到客户端1从Broker3重新连接,然后在CONNECT阶段触发离线消息推送,一样可以接收到全集信息,本应该收到的数据并不会减少,如下图所示。

同时我们可以推测百度QoS1的收发实现,一定是写入HBase成功以后,再回复PUBACK;一定是下发消息成功(收到PUBACK)以后,再删除HBase的数据。
非持久化Session的处理方式
连接阶段
连接阶段没有相应描述,推测会在连接节点Broker上创建连接信息,但并不会同步给其他节点:

订阅消息流程
订阅消息没有相应描述,推测:
- 同样会利用Kafka进行订阅事件分发消费(更新订阅树),因为其他节点需要知道这个Broker上有客户端订阅了某个主题
- 但只在连接节点Broker上创建Session记录订阅信息和虚拟队列(更新Session),并且虚拟队列直接用内存来做,因为非持久化Session离线后不需要保存

发送消息流程
发送消息没有相应描述,推测:
- 客户端2发送一条消息给Broker2
- Broker2发现Broker1上有订阅者,因此将消息直接发给Broker1
- Broker1发现客户端1订阅了这个主题,将数据写入对应内存队列
- Broker1向Broker2回送一个Event,表明自己成功收到了数据并处理完毕
- Broker1从内存队列读取数据,然后将数据下发给客户端1
Event Service的数据压缩
Event Service会将持久化Session相关的数据(连接/断开连接事件、订阅/取消订阅事件)放入Kafka,当一个新的Broker加入集群,首先就要将持久化的Session信息全部加载。如果都是从Kafka主题头部开始消费数据的话,可能会花费很久的时间,因此需要对数据进行压缩。压缩做的事情就是保存这些事件消费后产生的最终效果,举个例子,比如订阅我们用订阅树来存储,如果从头消费,需要一根一根分支去插入、删除,模拟客户端做的操作;如果直接保存最后的订阅树在内存中的结果,这些操作就都可以不做了。消费流程解释得不详细,这里按我的理解和推测来描述,流程图如下:
- Broker新上线,从HBase取出压缩的数据,构建初始数据结构
- 从检查点开始消费Kafka的数据
- 消费到最新一条后,上线完成,新的Broker和其他Broker没有任何区别
原文中只描述了SUBSCRIBE/UNSUBSCRIBE事件的压缩,我认为CONNECT/DISCCONECT事件的数据也需要进行压缩,压缩原理一致。
基于HBase的分布式消息队列
HBase本身不提供Queue的功能,但我们可以利用HBase的特性来实现Virtual Queue的概念。
整体描述:如图所示,有4个客户端,每个客户端对应一个虚拟队列Virtual Queue。我们为每个客户端分配一个唯一的(unique)QueueID,这样每个队列可以用QueueID+单调递增ID来组合成一个唯一的RowKey。为了保证写入的均匀性,避免热点问题,我们设计合理的唯一ID前缀(Prefix)来将这些RowKey均匀地分布到不同的Region。为了实现Queue的功能,我们在HBase上定义一个协处理器(CoProcessor),用作创建Queue、管理Queue的入队出队等操作、删除Queue、修改Queue的配额等等,HBase的Coprocessor类似于Redis的Lua脚本。
Region Split算法
作用
我们希望所有的Queue能够均匀地分布到各个Region里面去,需要设计一个特殊的前缀作为分割条件(PatitionKey → Region)
名词解释
- TenantID:百度IoT采用的多租户架构(将在后面叙述),所以有一个TenantID,对于一个企业而言这个ID是常量。
- clientID:MQTT协议的clientID,百度用的是单调递增的64bit Long
- QueueID:前文提到的一个客户端对应一个队列,用于唯一标记客户端队列的ID
算法流程
- 定义客户端的QueueID为reverse{clientID}_TenantID,其中reverse的含义是字符串反转。
- PartitionKey设定为log2(REGION_NUM),其中REGION_NUM是预期的region数量
算法解析
百度的clientID是系统生成的、单调递增的64位长整型,加入预期region数量为128个的话,可以用前log2(128)=7比特的变化来映射到对应region。但由于数字的前面高位部分变化幅度低(要增长1W个数字万位才会进1),而后面低位数字变化剧烈(每增长1个都会变),我们需要的只是0~127的剧烈变化,所以将clientID进行翻转,取前8bit来做映射。
保证写入消息的有序性
我们为每个客户端的每条消息都分配一个唯一ID,记为QueueID_ID,其中QueueID为队列ID( reverse{clientID}_TenantID ),后面的ID为单调递增64位长整型ID。例如一个客户端的消息ID可能是:3134_BAIDU_234,代表BAIDU这个租户下的第3134个客户端的第234条消息。
消息都是批量(batch)写入的,当批量写入Coprocessor后,先获取该Queue的锁,然后分配ID,再将数据写入HBase,最后释放锁。这里的锁粒度是Queue级别(客户端级别),可以保证多个Broker并发写入一个客户端的Queue时不会发生冲突。
读取Queue数据
我们会为每个Queue保存该Queue在HBase的最小ID、最大ID,如果该Queue的最小最大ID在内存缓存中过期或丢失(比如很久没有读写队列消息了),就通过HBase的scan操作来重新获取一次最小最大ID,再缓存在Cache里。每一次读取特定长度的数据,保证每次数据的量级不会太大。读取的时候并不需要锁,因为读取只可能是客户端自己在读取,任何时刻读请求只可能来自一台机器的一个客户端。
删除Queue的数据
对于已经读取的数据,需要删除掉。由于我们的数据都是有序的,所以删除的时候只需要告诉Coprocessor删除多长的数据,然后根据最小ID、offset可以计算出要删除的RowKey,然后执行batch delete即可。删除同样不需要锁,任何时刻删除请求只可能来自一台机器的一个客户端。
HBase的使用考虑
由于HBase不存在官方的异步读写库(async library),目前只有openTSDB提供一个版本,而百度IoT利用coprocessor增加了一个新的endpoint,openTSDB的asnyc library却并不支持coprocessor,所以百度IoT自己扩展了async的库,最终用的自己研发的asnyc library的coprocessor库处理数据。
同时,MQTT的消息属于快速消费(short lived)的消息,基本上写入后会被立刻读出,所以百度做了2.0版本,做内存压缩(in memory compaction),不需要将数据写入HFile,只需要写WAL日志,这样可以极大的降低HDFS文件系统的IO,解决了HDFS文件系统瓶颈问题,不过这个版本还没有正式发布。
相关参考资料:
提供多种Queue的选择
基于HBase的这种Queue更适合小型客户端,比如APP、嵌入式IoT设备等等,对于大规模扇入场景,例如有一个后端服务需要统计数据,要求100W设备都往同一个主题发送消息,基于HBase的Queue只能有一个TCP来处理数据,后端服务肯定处理不过来会有大量消息堆积。所以百度还推荐使用Kafka来应对这种情况,将数据发往Kafka主题,然后利用Kafka的负载均衡客户端来并发消费消息。除了HBase、Kafka、内存,百度IoT还提供Redis做Queue。
多租户架构
百度是一个大平台,肯定不止为一家公司服务,所以用多租户架构来提供IoT Broker功能。
一个IoT Hub上会有很多租户的MQTT Broker, 每个Broker对应一个tenant,每个Broker都有自己的Authentication Service, Session manager, Queue Service,以及很多其他的公共服务,比如Unique Id Generator,Backend Sorage Service等等。当客户端通过MQTT/TCP建立连接,云端通过username来区分对应哪个tenant,因此要求username必须为{tenent Name}/{client Name},取出username、password之后,先算出对应client的tenant name,然后拿到该tanent对应的Broker实例,调用该Broker的Auth Service验证客户端身份。
Baidu IoT Hub vs EMQ官方测试结果
测试信息
- 测试机配置
| 配置参数 | 值 |
|---|---|
| Vender ID | Genuine Intel |
| CPU Family | 6 |
| Model | 45 |
| Model Name | Intel(R) Xeon(R) CPU E5-2620 0 @ 2.00GHz |
| 核心数 | 12 |
| 内存大小 | 132137288KB(约126GB) |
- 测试场景:一半PUBLISH和一半SUBSCRIBE,每一个pub对应一个sub,也就是说通过唯一主题关联起来,这种场景是对MQTT协议最严格的考验,其他场景相对来说CPU消耗会少一些
- 消息Payload大小:1024B(1KB)
- Queue类型:内存Queue(因为EMQ只有内存Queue)
文中并没有提到EMQ的版本。
测试结果
- MPS:message per seconds,每秒消息量。由于Pub和Sub是一一对应的,所以这里指的消息量是PUBLISH的QPS,总体QPS是这个值的2倍。
| 产品 | 连接数 | 预期MPS | 实际MPS | 平均CPU IDEL | 平均时延(ms) | 丢失率 |
|---|---|---|---|---|---|---|
| 百度 | 50万 | 20K | 19.2K | 34% | 383 | 0% |
| EMQ | 50万 | 20K | 19.2K | 26% | 1821 | 0% |
| 百度 | 50万 | 10K | 9.2K | 58% | 289 | 0% |
| EMQ | 50万 | 10K | 9.2K | 44% | 281 | 0% |
| 百度 | 20万 | 50K | 42.5K | 14% | 381 | 0.0000314% |
| EMQ | 20万 | N/A | 测试未返回 | |||
| 百度 | 20万 | 40K | 39.7K | 19% | 409 | 0% |
| EMQ | 20万 | 40K | 38.4K | 10% | 17456 | 0.0349% |
| 百度 | 20万 | 20K | 19.7K | 37% | 152 | 0% |
| EMQ | 10万 | 20K | 19.7K | 33% | 449 | 0% |
| 百度 | 10万 | 50K | 48.9K | 13% | 315 | 0.000272% |
| EMQ | 10万 | 50K | 31.7K | 11% | 8014 | 0% |
| 百度 | 10万 | 40K | 39.7K | 19% | 209 | 0% |
| EMQ | 10万 | 40K | 31.7K | 11% | 8014 | 0% |
| 百度 | 10万 | 30K | 29.9K | 26% | 152 | 0% |
| EMQ | 10万 | 30K | 29.9K | 19% | 2727 | 0% |
| 百度 | 10万 | 30K | 19.8K | 37% | 113 | 0% |
- 可用MPS对比(无丢包、时延小于0.5s)
| 连接数 | 百度可用MPS | EMQ可用MPS |
|---|---|---|
| 10万 | 40K(19%IDLE) | 20K(24%IDLE) |
| 20万 | 40K(19%IDLE) | 20K(33%IDLE) |
| 50万 | 20K | 10K |
官方测试结论
同等连接数下,百度Broker的可用最大吞吐量在EMQ的1~2倍之间。
百度IoT:MQTT_Broker架构设计

